
Introduced on February 5th, 2026, Claude Opus 4.6 is Anthropic’s newest AI model. It improves on the skills from Claude Opus 4.5, and it even outranks other high-performing competitors like ChatGPT-5.2 and Gemini 3 Pro. Let’s take a closer look at what this update has to offer.
What’s New with Claude Opus 4.6?
Claude Opus 4.6 specifically focused on improving knowledge work, agentic search, coding, and reasoning from the previous model. It’s able to plan more carefully, operate more reliably, sustain agentic tasks for longer, and review and debug better than before.
With these improvements, Claude can now better assist with everyday work tasks, such as running financial analyses, doing research, and creating documents, spreadsheets, and presentations. Claude’s Cowork helps the platform multitask autonomously to efficiently get tasks done.
A few key updates include:
- Adaptive Thinking: Rather than only enabling or disabling extended thinking, Claude decides when deeper thinking is beneficial.
- Effort Levels: Users can choose from low, medium, high (default), and max effort levels to find one that works best for them.
- Context Compaction: The platform automatically summarizes and replaces older context to help Claude perform longer tasks.
- 128k Output Tokens: This new version supports outputs of up to 128k tokens so Claude can better complete larger-output tasks.
Overall, the newest version of Claude elevates all the skills from Claude Opus 4.5. Plus, with the recent announcement that Claude won’t be implementing ads, this platform is becoming more popular than ever.
How Does This AI Model Compare?
The Claude Opus 4.6 system card indicates that this model not only outperforms its previous versions, but it’s also better than the industry’s next-best model (ChatGPT-5.2) in many ways. Its knowledge work score, agentic search accuracy, agentic coding accuracy, and multidisciplinary reasoning accuracy all ranked higher than current ChatGPT, Gemini, and Sonnet models.
Long-context retrieval and safety are just a few of the key aspects Claude Opus 4.6 improved on significantly.
Long-Context
One aspect that AI models often struggle with is context. AI performance often degrades as conversations go on, causing older parts of the conversation to gradually be forgotten or not considered.
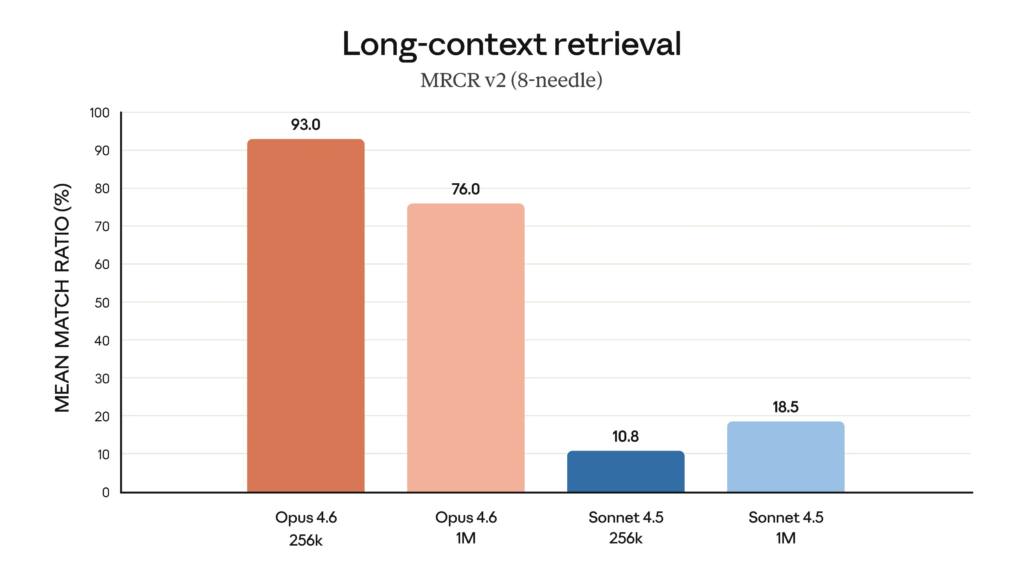
Claude Opus 4.6 scored a 76% mean match ratio for long-context retrieval while competitor Sonnet 4.5 only scored 18.5%.
Safety
Claude Opus has made huge strides in safety in recent models. Opus 4.1 scored almost 4.5 out of 10 for overall misaligned behavior, but Opus 4.6 scored less than 2, which is better than Sonnet 4.5 and Haiku 4.5. This shows that Anthropic is considering new safety features while enhancing intelligence.
Other Comparisons
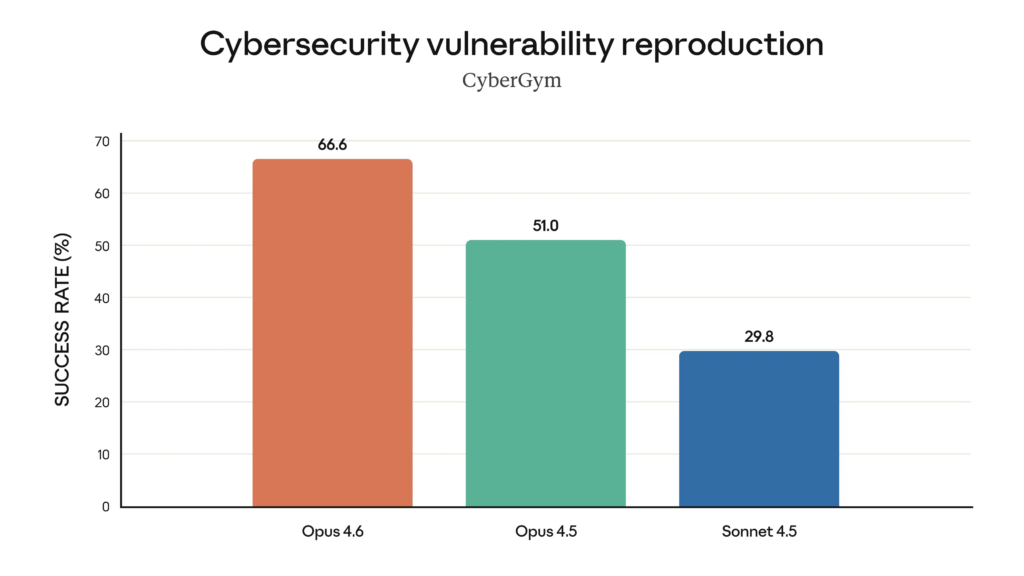
Anthropic collected lots of data to compare Claude Opus 4.6 to past models and other AI platforms. This data shows that Opus 4.6 is better than Opus 4.5 and Sonnet 4.5 at software failure diagnosis, long-term coherence, cybersecurity vulnerability reproduction, and computational biology.
Keep Your Brand Visible in AI Searches
AI platforms like Claude continue to grow in accuracy and abilities. Therefore, people use these models frequently in their daily lives. To ensure your brand reaches a wide audience, focus on visibility in AI searches.
Contact Avenue Z today so we can help your brand navigate AI optimization strategies.
The AI-First Agency
Win AI search, grow revenue and build reputation through PR and digital marketing.




